
Predicción de homicidios con arma de fuego utilizando ANN
Autores
Sergio Ivvan Valdez Peña¹ svaldez@centrogeo.edu.mx, Omar Esteban Corona Mindiola² esteban.corona@alumnos.udg.mx, Jorge Paredes Tavares¹ jparedes@centrogeo.edu.mx
¹ Centro de Investigación en Geografía y Geomática Ing. Jorge L. Tamayo, A.C., CONACyT.
² Universidad de Guadalajara.
Resumen
En este reporte se utiliza una red neuronal artificial de perceptrón multicapa para predecir los homicidios por arma de fuego en los 50 municipios más violentos de México, usando 17 delitos de la base de datos del Secretariado Ejecutivo como predictores, encontrados mediante la correlación que tienen con el delito principal (homicidios). Se logró estimar el número de homicidios en los últimos 4 meses disponibles con un error máximo de 25%.
Introducción
México es el país número 37 en el índice de crímenes del año 2020 [4], esto afecta directamente la calidad de vida de la población. De acuerdo con el Better Life Index de la OCDE, México se ubica en la posición 38 de 40 tanto en el índice global como en la tasa de homicidios de los países estudiados.
A partir de predictores o variables de entrada otros delitos reportados el mes anterior, buscamos predecir el número de homicidios por arma de fuego en los 50 municipios más violentos de México (de acuerdo a los datos del 2019). Para ello, se usó una red neuronal del tipo retropropagación la cual toma varios valores de entrada en este caso los delitos de un mes anterior y regresa un único valor, correspondiente al número de homicidios que se esperarían el mes siguiente.
Método
Se utilizaron los datos de incidencia delictiva desde el año 2015 hasta agosto del 2020 publicados por el gobierno federal a través del Secretariado Ejecutivo del Sistema Nacional de Seguridad Pública.
El primer paso fue depurar la base de datos, conservando las variables: clave y número de entidad, municipio y los delitos ocurridos en cada mes en función de su categoría. En la primera etapa, se utilizaron los años 2018 y 2019, uno como predictor y el otro para observar la relación que podría existir entre ambos. Para compararlos se utilizó todo el año 2019 y, a partir de él, usar un periodo de 12 meses diferido por 1 y 2 meses. En primera instancia este análisis solo se realizó para el municipio de Guadalajara, ya que, al ser uno de los más poblados del país podría sugerir como identificar cuales de los delitos están más correlacionados con los homicidios dolosos.
El primer filtro para escoger los posibles predictores fue comparar los homicidios cometidos con arma de fuego con los 98 delitos del mes anterior y seleccionar solo los que cumplieran una correlación mayor o igual a ±0.5, para esto se usó la función cor.test mediante los métodos “Pearson y kendall” [3], todo esto aplicado a datos normalizados de acuerdo a la división entre el máximo de cada delito.
Luego de observar que varios delitos cumplían con la condición impuesta se procedió a comparar todos los municipios y agruparlos por estados para ver las semejanzas entre estos. Para ello se generó un histograma de frecuencias que tomaba el número de veces que un delito se correlacionaba con los homicidios en los diferentes municipios del estado. De esta manera se obtuvieron 32 histogramas de frecuencias correspondientes a cada estado, como un ejemplo, se muestra en la Figura 1 el correspondiente al estado de Jalisco.
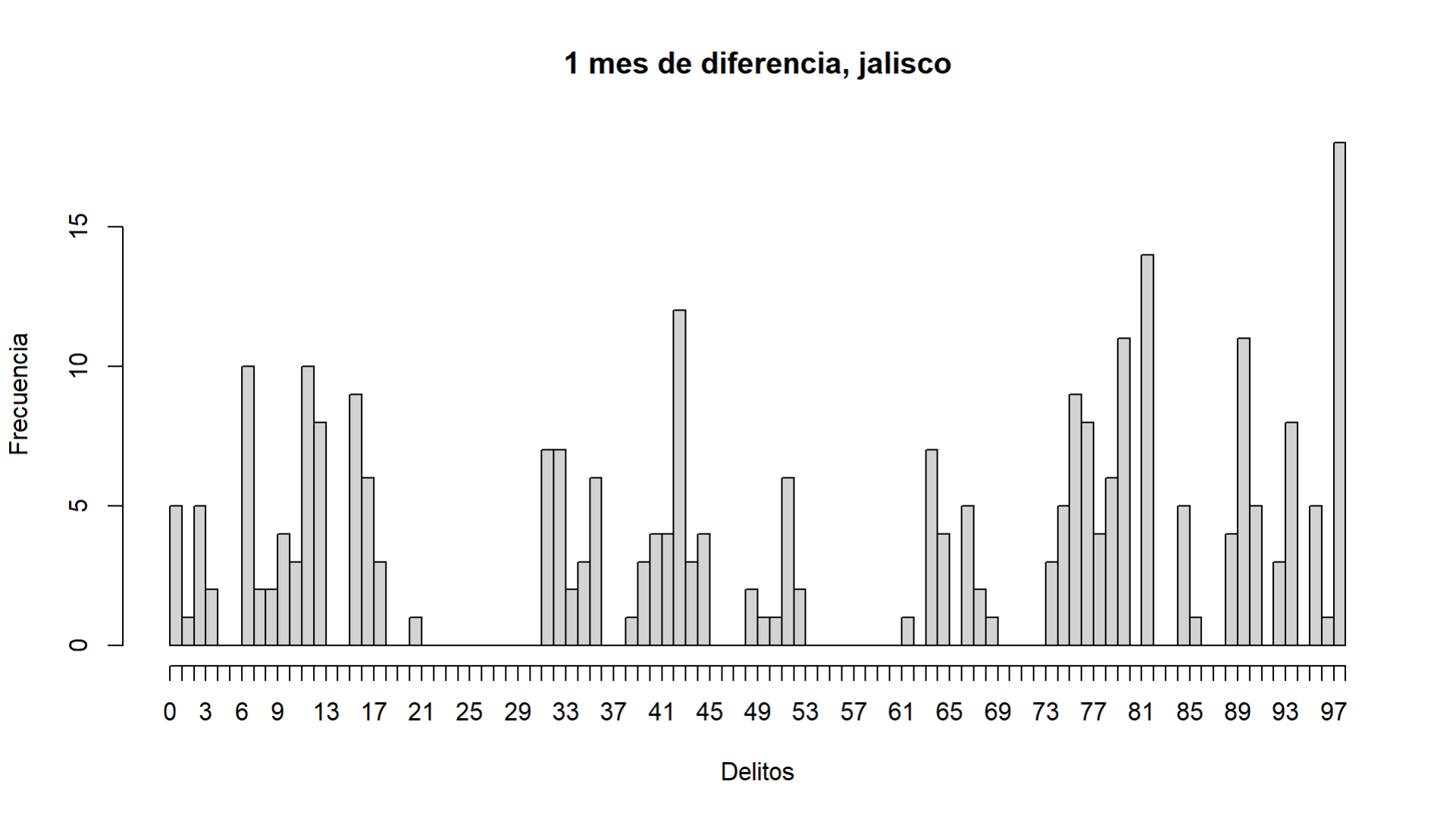
Figura 1. Histograma de frecuencias del estado de Jalisco.
Las frecuencias corresponden al número de veces en que un delito superaba la correlación mencionada anteriormente. De esta manera se identificaron los delitos que más se relacionaban con los homicidios con arma de fuego en los diferentes estados.
Posteriormente se procedió a separar los datos mediante dos métodos similares. El primero fue usando clustering del tipo K-means como se indica en [6] y de esta manera organizar los delitos en 5 grupos de posibles predictores, como se muestra en la Figura 2.
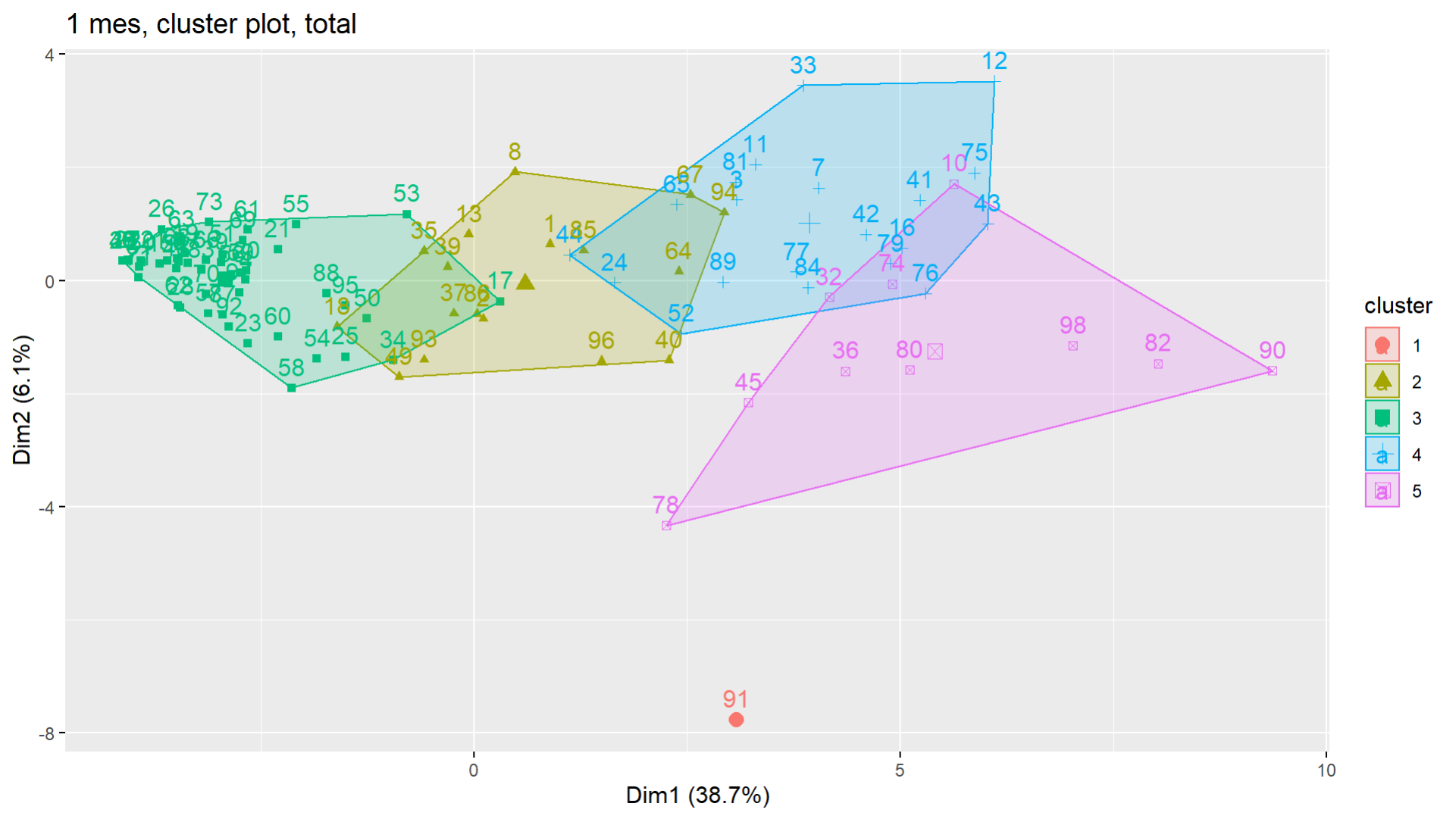
Figura 2. Grupos de posibles predictores.
Se observa en primera instancia que en realidad se trata de 4 grupos, sin embargo, se conservaron 5 para separar el dato anómalo que corresponde al estado de Yucatán. De estos 4 grupos, se escogió el clúster número 2, el cual contiene a los homicidios dolosos con arma de fuego (etiqueta 1). Este clúster contiene 17 delitos que se enlistan en el anexo I.
Posteriormente se creó un data.frame para entrenar y poner a prueba una red neuronal. El contenido de ese data.frame fueron los 54 meses de información disponible, con una diferencia temporal de un mes entre los delitos seleccionados y los homicidios cometidos con arma de fuego. Se usaron los primeros 50 meses como datos de entrenamiento y los 4 restantes como prueba. La red neuronal fue creada con la función neuralnet, que utiliza el método de retropropagación [2] para calcular las salidas.
Para definir el número de neuronas a utilizar se hicieron 4 pruebas, una red con 4 capas de neuronas y otra con 5, que a su vez se aplicaron a una red con una columna temporal y otro sin esta (Figuras (3) y (4)). Utilizando gráficas de tipo violín para los errores de estas redes, se determinó la configuración que tuviera un menor error.
En todas las gráficas se trabajó con un error absoluto medio, aplicado a los resultados normalizados.
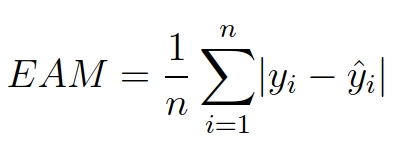
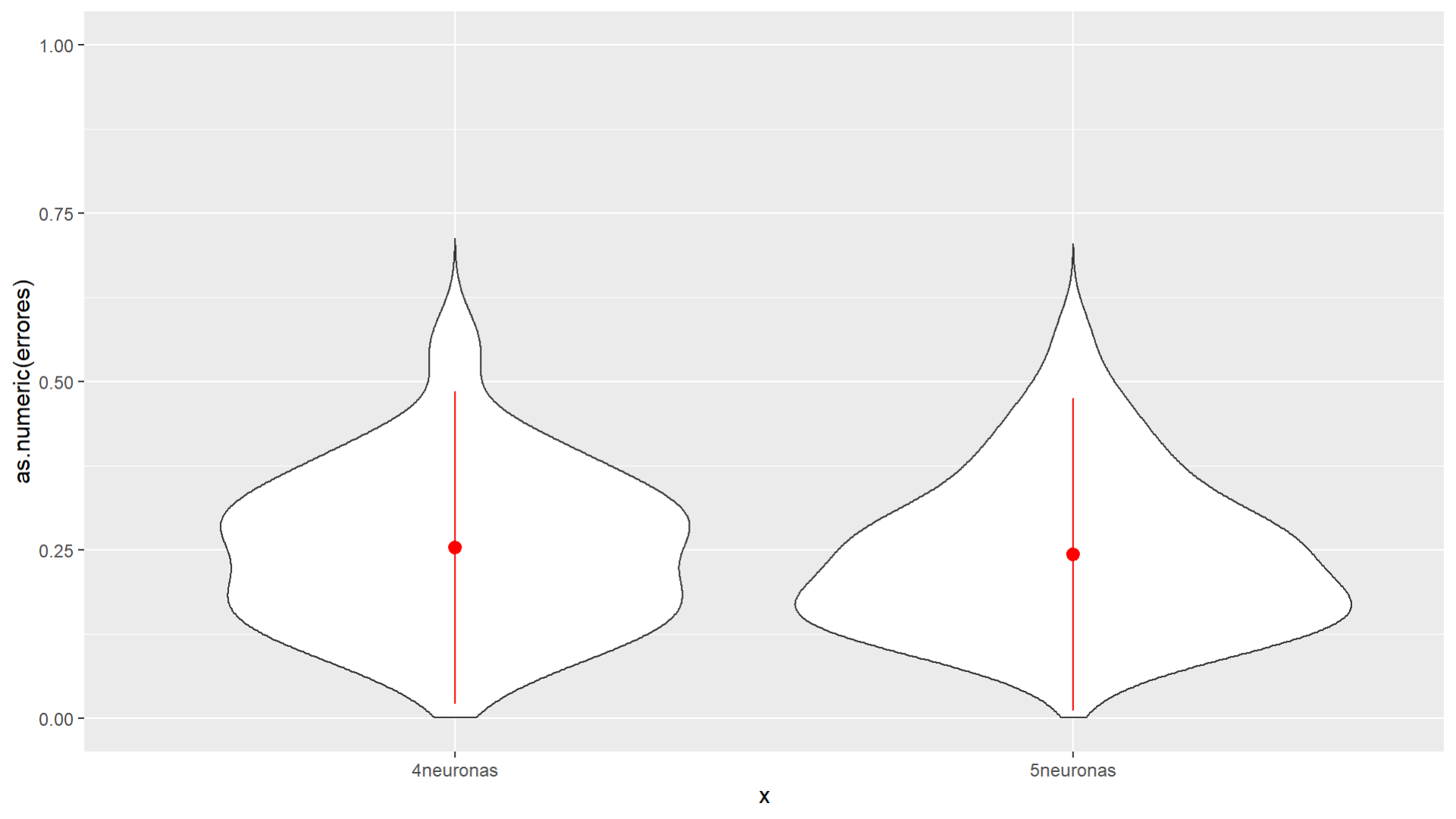
Figura 3. Errores sin columna temporal.
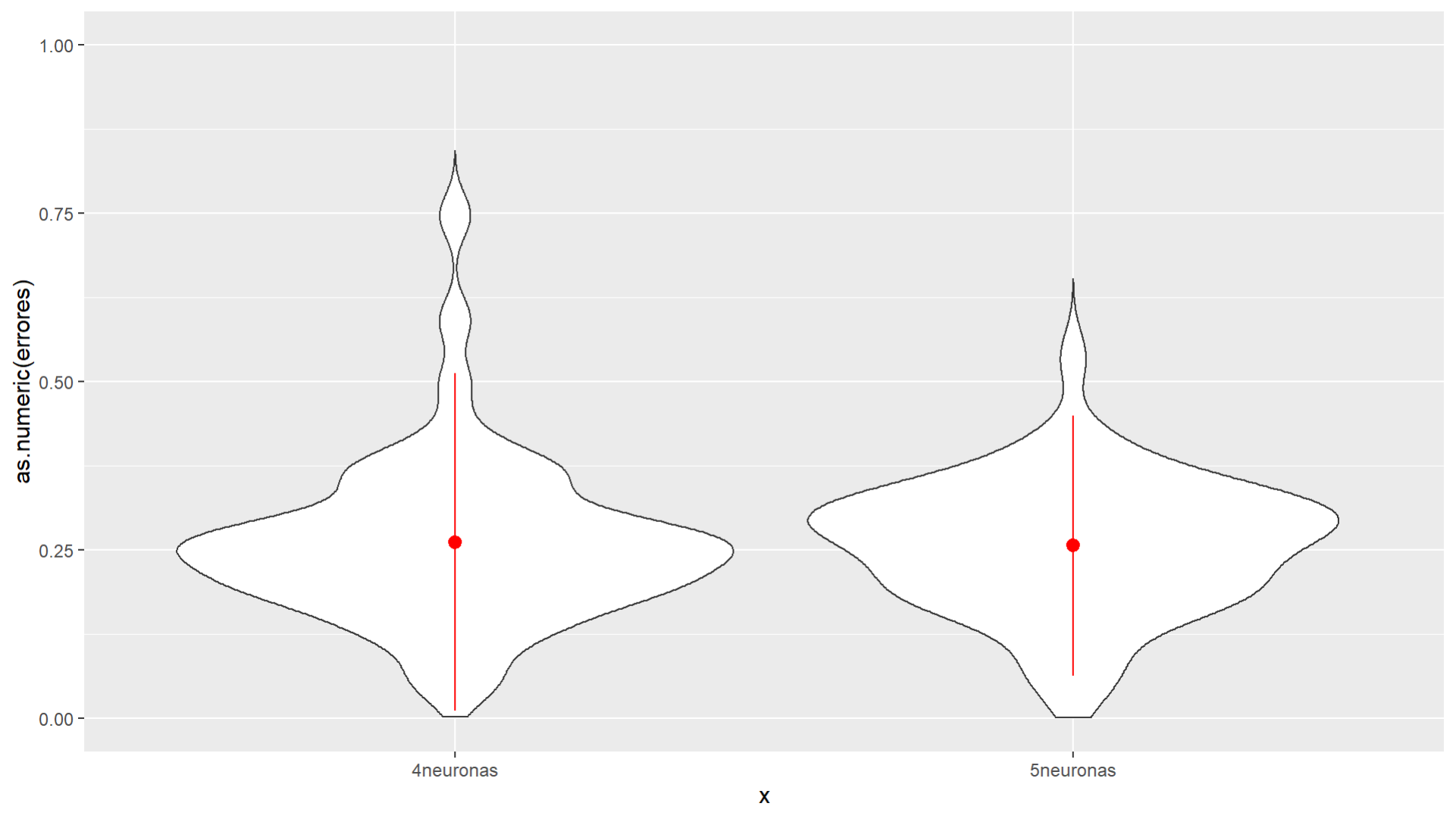
Figura 4. Errores con columna temporal.
La configuración con una columna temporal y 5 capas de neuronas da mejores resultados, pues la masa de densidad en los errores es más común en valores cercanos a 0.
La manera correcta de escoger los números de neuronas en cada capa no se encuentra dentro de los alcances de este estudio por lo que se decidió hacerlo mediante el siguiente vector: 34,17,9,5,1, que corresponde al doble del número de delitos utilizados y luego disminuyendo por la mitad hasta llegar a 1.
Para mejorar los resultados se incluyeron datos de municipios vecinos que pudieran compartir alguna relación. Para escoger dichos vecinos lo que se hizo fue comparar entre los 50 municipios principales y sus municipios adyacentes, la correlación entre los 17 delitos que ocurren en el municipio principal y los adyacentes, seleccionando aquellos en los que se encontraba una correlación más alta, siempre mayor a 0.7. Obteniendo así la tabla de adyacencias del Anexo II.
Se agregaron los delitos de los municipios vecinos a los datos de entrenamiento en una nueva red y se compararon mediante gráficas de tipo violín, si las predicciones mejoraban después de haber compilado la red 10 veces, se seleccionaban estos datos.
Resultados
Se realizó una representación cartográfica de los resultados obtenidos, esto para buscar relaciones espaciales que indicaran fallos en el modelo. Los datos con los que se generaron dichos mapas se encuentran anexados en el Anexo III.
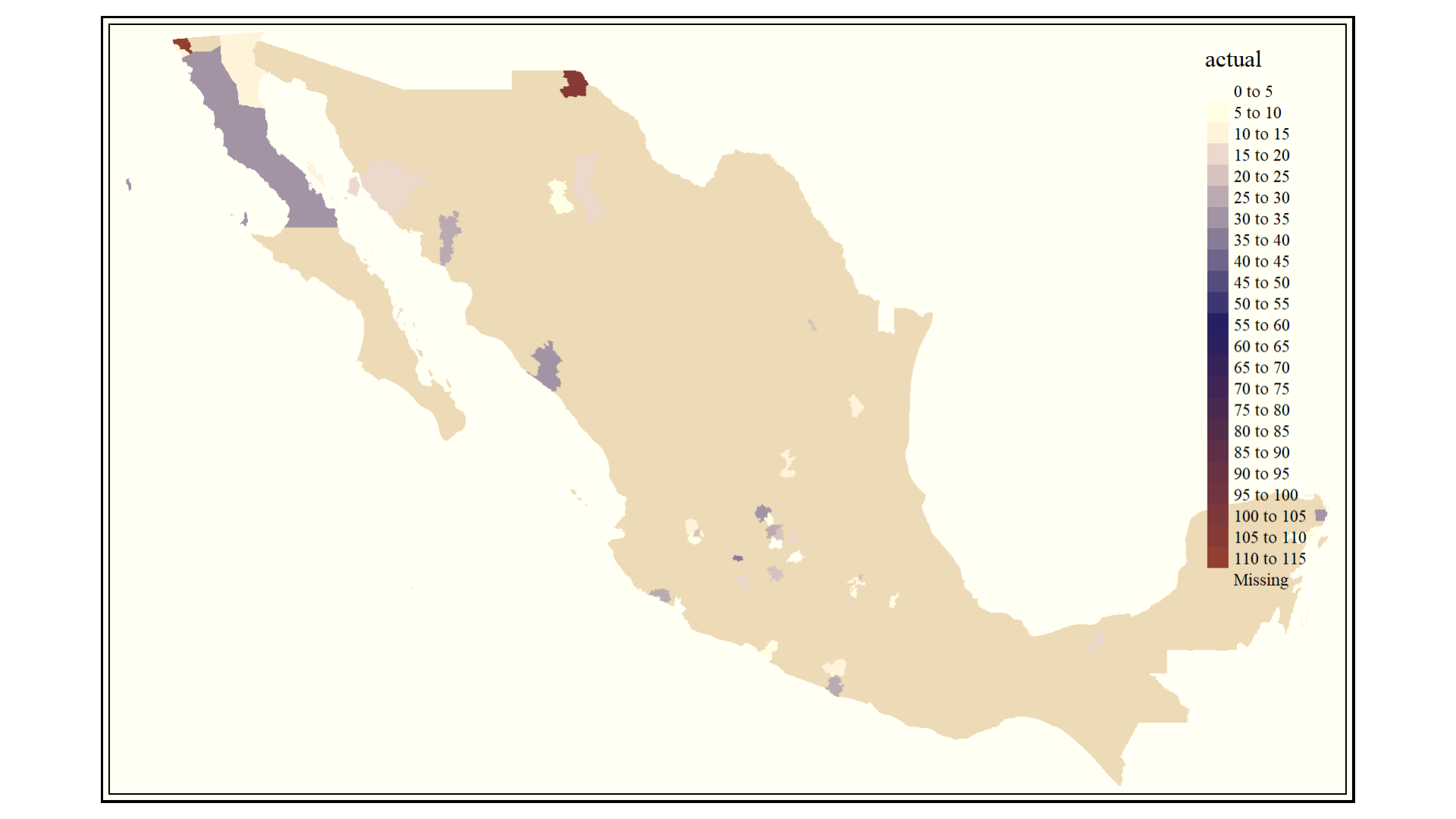
Figura 5. Homicidios reales por arma de fuego en el mes de marzo del 2020.
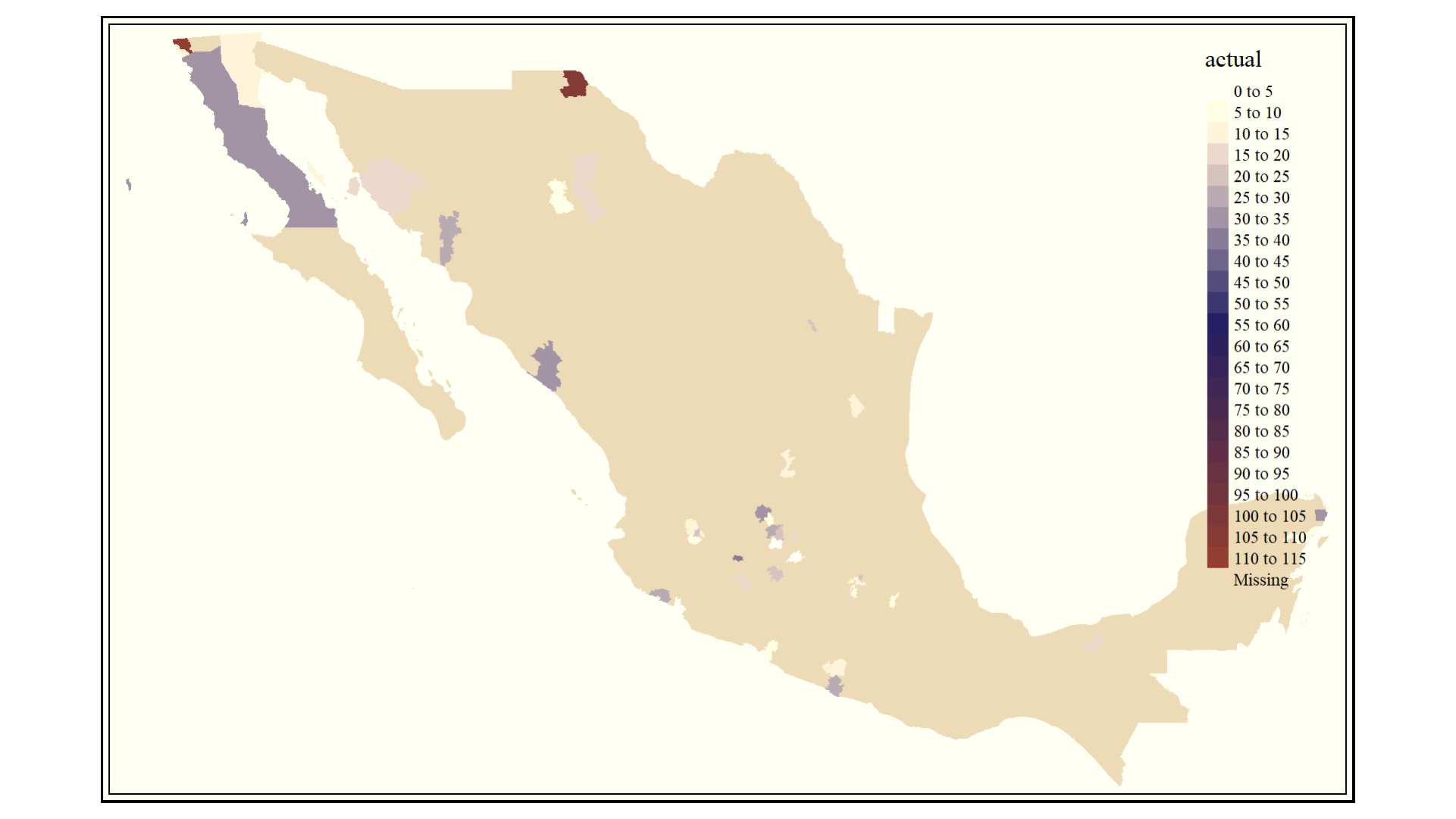
Figura 6. Predicciones de homicidios por arma de fuego en el mes de marzo del 2020.
Discusión
Según los datos que se muestran en el Anexo IV se logró una buena predicción, pues en la mayoría, los errores no superan el valor del 0.25, y en los que, si lo hacen, existen varios factores que causan esos valores atípicos, los cuales discutiremos a continuación.
No todos los resultados presentados se obtuvieron usando datos de municipios adyacentes, pues algunos de ellos no tuvieron la suficiente correlación para tomarlos en cuenta, y en otros casos, sus resultados no mejoraban al utilizarlos.
Los municipios que no incluyeron vecinos por falta de correlación fueron: Juárez, Acapulco de Juárez, León, Cajeme, Chihuahua, Uruapan, Hermosillo, Reynosa, Centro, Celaya y Cuauhtémoc.
Los municipios en los que se obtuvieron mejores resultados usando solo datos propios fueron: Tijuana, Manzanillo, Álvaro Obregón, Salamanca, Guadalajara, Chimalhuacán y Solidaridad.
Uno de los principales factores que se debe tomar en cuenta, es que los meses en los que se hizo esta predicción se encuentran dentro del periodo de la pandemia ocasionada por el virus COVID-19, por lo que en algunos municipios esto causó un decaimiento en el número de homicidios; sin embargo, es posible que los delitos que se usaron para la predicción mantuvieran constantes, arrojando así valores de predicción más elevados de los que realmente sucedieron, un ejemplo de esto es el municipio de Uruapan, que pasó de tener entre 18 y 15 homicidios a solo 4 en el último mes.
Tras comparar el municipio que tiene un error más bajo contra el que tiene un mayor error, dichos municipios son León con un error de 0.040 y Ensenada con un error de 0.253, sin embargo, el error tan grande por parte de Ensenada se debe a que la predicción del primer mes es bastante mala, en comparación con los meses siguientes, por lo que en su lugar podríamos poner al municipio de Benito Juárez, en el cual los resultados si son muy distintos a los reales. Una primera diferencia entre estos dos municipios es la cantidad de población entre ambos, por lo que se podría inferir que entre más elevado sea el número de habitantes se obtienen mejores resultados, no obstante, Manzanillo tiene una población muy inferior a la de León y las predicciones que se hicieron en dicho estado son bastante aceptables, por lo que el factor de población queda descartado.
Los resultados muestran que en los municipios donde existe un error más grande suelen haber valores aleatorios en sus delitos, un ejemplo de esto es Benito Juárez, que pasa de tener menos de 100 robos a negocios con violencia a casi 400, este cambio se produce de un mes a otro alterando de esta manera la tendencia. Este comportamiento se encuentra también en otros municipios, y es un factor a considerar para la validación del modelo. Se desconoce si esto se debe a errores en la captura de datos o si en realidad así es la varianza de delitos en dichos municipios.
Conclusiones
Se encontraron 17 delitos que sirven muy bien en algunos de estos municipios para predecir los homicidios con arma de fuego.